はい、ごめんください。Microsoft Clarity(クラリティ)大好きコスギです。
この記事は Ihab Rizk さんによって書かれた Microsoft 社の公式記事「Clarity Now Surfaces Robots.txt Violations in Bot Analytics」を和訳しつつ、私の考えなども入れたものです(和訳公開の許可を得ています)。ノイズなく読みたい方は以下からどうぞ。
以下に、要点を3行で。
- Bot Analytics に robots.txt 違反を検出する機能が追加され、ルールを無視しているボットがわかるようになった
- 違反の割合・時系列のトレンド・オペレーターやボット名別の内訳まで確認できる
- 利用には WordPress プラグインか対応CDN(Fastly/Amazon CloudFront/Cloudflare)の接続が必要
AIツールやクローラーがコンテンツの発見において大きな役割を担うようになってくると、事業者はトラフィックの量だけでなく、それ以上の情報を知る必要があります。どのボットが自社のコンテンツにアクセスしているのか、そのボットが何にアクセスしようとしているのか、そして、そのプラットフォームが robots.txt で定義されたアクセス方針をきちんと守っているのか、ということです。
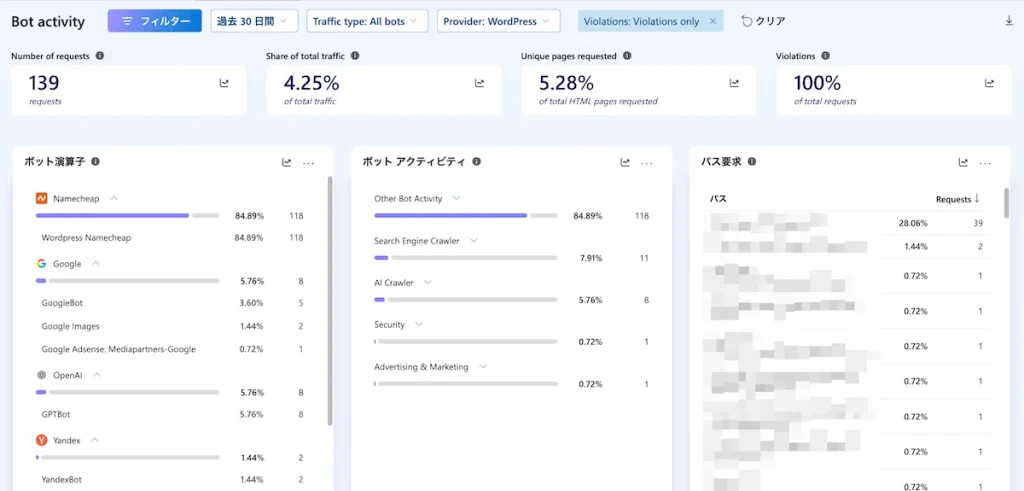
今回の Bot Analytics ダッシュボードのアップデートにより、Clarity は robots.txt のボット違反を検出し、見える化できるようになりました。ボットがアクセス禁止のURLにリクエストしたタイミングを確認したり、違反の傾向を時系列で追跡したり、オペレーター・ボット名・アクティビティタイプでアクティビティを絞り込んだりすることで、どのクローラーがルールを無視しているのか、そしてどのコンテンツが規約違反のアクセスを集めているのかを把握できます。
コスギ注
前回、Bot Analytics のアップデートをまとめた記事を書いたんですが、その中で「CDN違反の検出」として触れていた機能の詳細版が、今回のお知らせかなと。Microsoft はAI関係の機能には本腰を入れているのか、本当にハイペースでリリースしますね。
そもそも robots.txt がよくわからない方向けに一言だけ補足すると、robots.txt は「このサイトのこの場所は、ボットに見てほしくない/見てほしい」をクローラーに伝えるための、ごく簡単な仕組みです。
ただし、robots.txt に書かれていることは「お願い」であって「強制力」ではありません。マナーの良いボットは守りますが、守らないボットもいます。今回の機能は、その「守っていないボット」を名指しで見つけられるようにしましたよ、という話です。
ちなみに、先述のスクリーンショットはこのブログの開発環境のデータなので、「マナー違反のボットが多く来ている」というより「関係者なんだけどめっちゃ目をつけられている」みたいな感じです。本番公開しているサイトには違反ボットのデータがなくてですね……
何が新しくなったのか
今回のリリースでは、クローラーの挙動をより明確に把握できるようになり、単に「ボットが何回サイトに来たか」だけでなく、「コンテンツへのアクセス方針とどう向き合っているか」まで評価できるようになりました。Clarity はボットのリクエストをサイトの robots.txt の指示と照合し、規約を守っているトラフィックと違反しているトラフィックを分けて、より深く分析できるようにします。
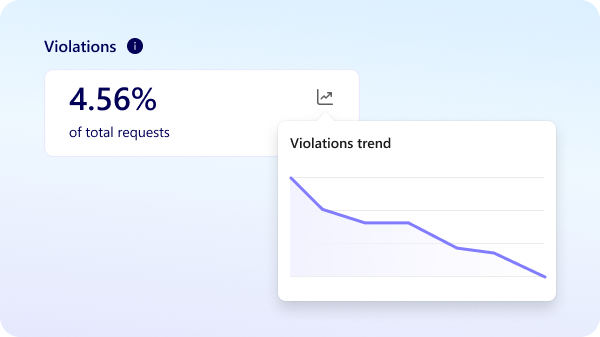
- 「Violations(違反)」カード
ボットによる全リクエストのうち、違反しているとされるパターンが占める割合を表示。どれくらいのボット活動がクロールルールを無視しているかを、ひと目で把握できる - Violations(違反)トレンドライン
違反パターンの時系列での変化を追跡できる。急増のタイミングを見つけたり、常習的な違反元を監視したり、違反行為が増えているのか落ち着いてきているのかを把握できる - オペレーター・ボット名・アクティビティタイプでのフィルタリング
データを絞り込み、どのオペレーターやボットが robots.txt の指示に違反しているかを特定し、その原因となっているアクティビティの種類を切り分けられる - ボットが実際にアクセスしている内容を確認
違反を発生させているURLやパスを確認し、クローラーが価値の高いコンテンツや制限付きのリソース、本来アクセスされるべきではない領域にアクセスしようとしているかを把握できる - 規約を守っているリクエストと違反しているリクエストの比較
クロールの方針を尊重しているボットと、そうでないボットを区別し、AIツールやクローラーが公開コンテンツとどう関わっているかを、より完全な形で把握できる - コンテンツ単位での可視化
パスやコンテンツタイプ別に違反のアクティビティを分析し、どのコンテンツが規約違反のボットトラフィックを引き寄せているのか、対策や緩和策が必要な箇所はどこかを特定できる
これにより、事業者はAIの可視性をより実用的な形で評価できるようになります。リクエスト数だけに頼るのではなく、AIシステムが自社の意向どおりの形でサイトを発見しているか、どこで一線を越えているか、コンテンツのどの部分が最も規約違反のアクセスを集めているかを把握できるようになるのです。
コスギ注
Google サーチコンソールでは「意図せずブロックしていないか」がわかりますが、Microsoft Clarity の Bot Activity では「ルールを無視して侵入してきているヤツがいないか」がわかるようになった、という違いがあります。
ボットが実際にアクセスしているURLを確認できるのは、使えるかも?「ウチのお問い合わせフォームの確認画面とか、会員限定ページにまで読みに来てる!?」みたいな発見ができそうです。そうなると、本来見せたくないページまで外部に見られている可能性がある、とわかるわけですね。
中小企業のサイトだと、robots.txt 自体を管理していないケースも多いと思います。WordPress なら、SEO系のプラグインが自動生成していることに気づいていないとかもあるでしょうし。リニューアルや引っ越しのタイミングで内容が変わって、意図せず大事なページをブロックしてしまっていた……というのも、まれによくある話です。
この「違反」が急に増えたときは、相手(ボット)が悪いというより、自分側の robots.txt の記述ミスや、CMS側の自動生成設定が変わった可能性もセットで疑うのがいいと思います。
はじめるには
この機能を使う前に、プロジェクトの管理者がプロジェクト設定の AI Visibility セクションから、対応するCDNを接続しておく必要があります。対応CDNは、Fastly、Amazon CloudFront、Cloudflare です。
最新版の Microsoft Clarity プラグインを利用している WordPress サイトでは、AI Bot Activity は自動的に利用できるようになります。古いバージョンの Clarity プラグインを使っているサイトは、機能を利用するためにアップデートが必要です。
CDNの接続が完了したら、以下の手順で robots.txt 違反のインサイトを確認できます。
- Clarity でプロジェクトを開き、Bot Analytics ダッシュボードに移動する
- Violations カードを見つけて、robots.txt の指示に違反しているボットリクエストの割合を確認する
- オペレーター・ボット名・アクティビティタイプのフィルターを使って、調査したいクローラーや挙動に表示を絞り込む
- 違反しているURL・パス・コンテンツタイプを確認し、ボットが何にアクセスしているのか、どのコンテンツが規約違反のアクティビティを集めているのかを把握する
- 規約を守っているリクエストと違反しているリクエストを時系列で比較し、パターンを見極めながら、監視・対策・コンテンツ保護のワークフローを更新するかどうかを判断する
この機能は現在 Clarity で利用可能です。すでに Bot Analytics を利用している場合は、違反のインサイトはすぐに使い始められます。
コスギ注
Cloudflare の無料版でも対応できるようになったと前回の記事に書かれていたので、使える方は広がったのではないかと思いますが……WordPress + Microsoft Clarity プラグインの最新版を使っていても、CDNに WordPress を使えないケースもあるようです。ボットアクセスのセッション数が低いと使えない……??
一時的な不具合だと思いたいですが、そもそものセッション数もさほど多くなければ、AIボットによるアクセスも施策に活かせるほどのものではないので、まずは自社のコンテンツに向き合うほうが先かもしれませんね。
なお、AI Bot Activity の基本については、過去記事もあわせてどうぞ。

余談:「ルールを守らせる」ではなく「ルールを破る相手を知る」
今回の機能、「robots.txt を守らせる」機能ではないんですよね。あくまで「守っていない相手を見える化する」機能です。有名どころだと、ByteDance 社のクローラー や Perplexity のAIボットは robots.txt を無視すると言われていますね。今はどうなんだろう。
また、ユーザーが ChatGPT などのAIに「このページを要約して」と依頼すると、AIは「ユーザーから依頼されて来たので、私は人間です」という顔をしてアクセスしてきます。人間がニャーニャー鳴いたって、猫にならんのと一緒やないかい。
あと、インターネット上の安全を監視するために活動しているボットもいます。おまわりさんが戸締りを確認しに来ているようなものなので、これはまあ、問題ないでしょう。本当のおまわりさんなら。
robots.txt は、性質的には「お願い」です。法律でもなければ、技術的にブロックするものでもありません。守るかどうかは、結局相手のボット次第です。だからこそ、「誰が守っていて、誰が守っていないか」を知ること自体に価値が出てくるわけです。
これは、人間社会のマナーと同じようなもので、看板を立てたところで、見ない人・無視する人は必ずいますよね。それでも看板を立てるのは、見て守ってくれる大多数のためです。今回の機能は、無視する一部の存在を「知らないままにしない」ためのものです。
とはいえ中小企業のサイトにとって、「いますぐ違反ボットをブロックしよう」と意気込む必要はないと思います。まずは「誰が来ているか」を知るだけで十分です。そのうえで、本当に困る相手が出てきたら、CDN側のルールで個別に対応すればいい話。
わからなければ何もできませんが、わかれば対処のしようはあります。今回のアップデートは、その「知る」を一歩前に進めてくれるものではないでしょうか。










